 Latent Diffusion Model Overview
Latent Diffusion Model Overview
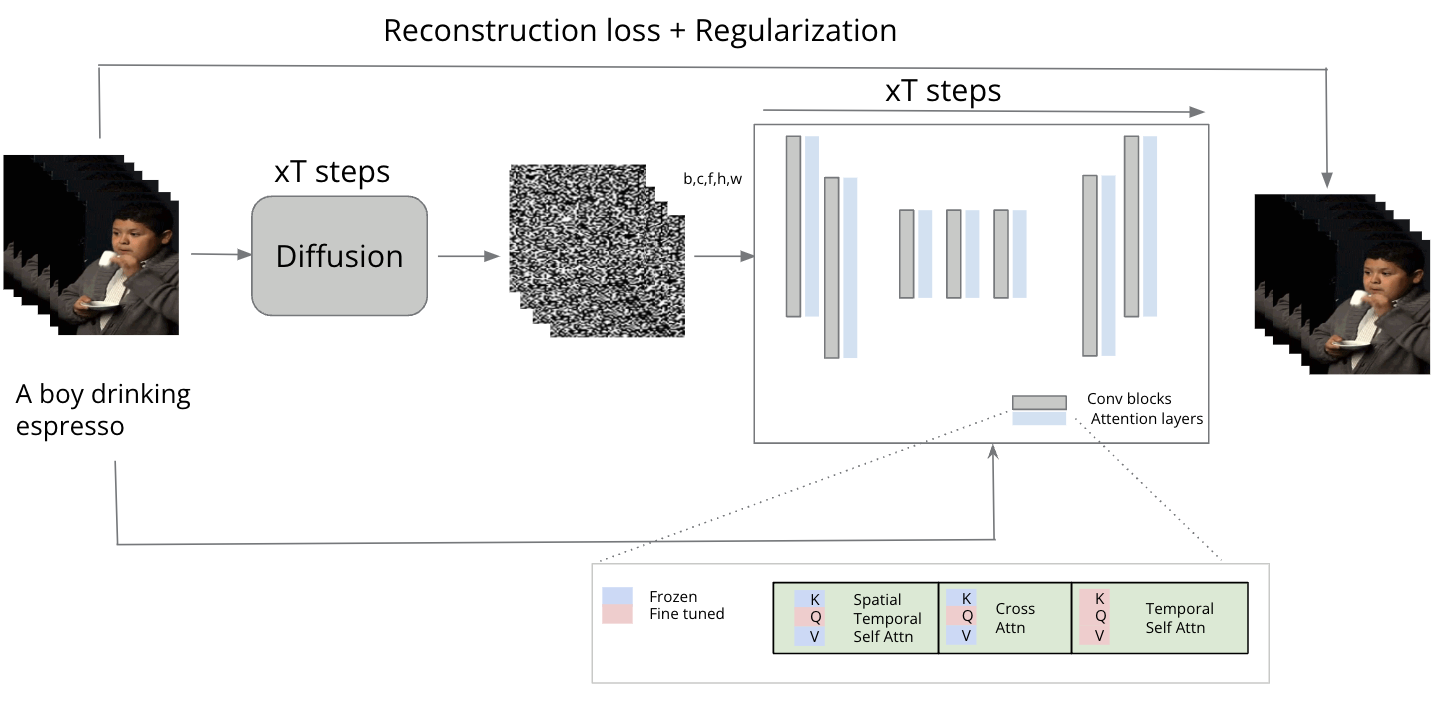
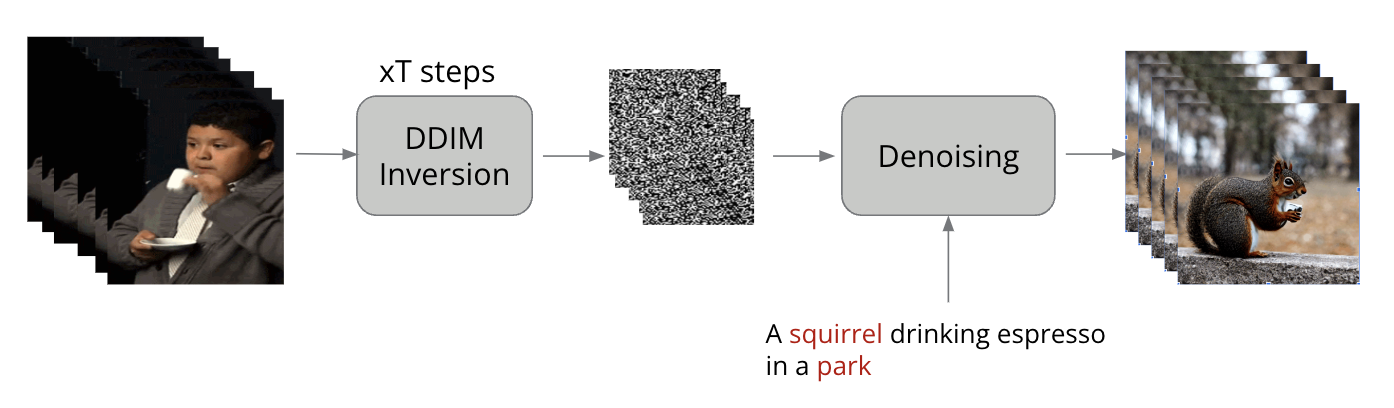
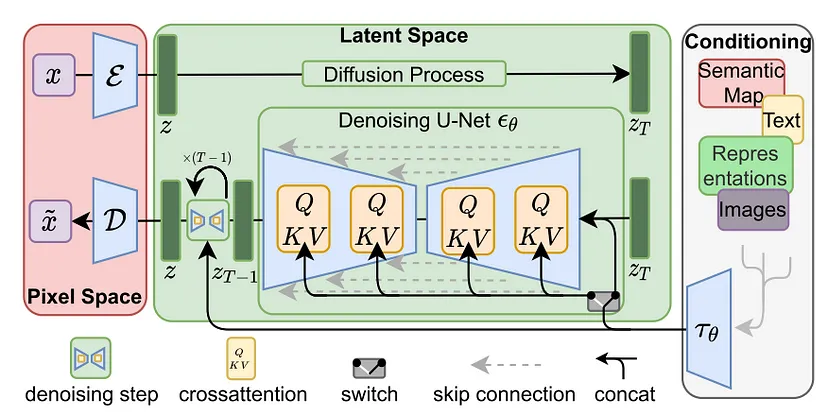
Latent Diffusion Models (LDMs), introduced by Rombach et al., represent a significant evolution within likelihood-based Denoising Probabilistic Models (DPMs), adept at capturing intricate data details for high-fidelity image generation. Traditionally, DPMs operated in pixel space, necessitating substantial computational resources and time, and suffering from slow, sequential inference processes. LDMs address these challenges by utilizing a two-phase training strategy: initially, an autoencoder compresses the image into a perceptually consistent latent representation, significantly reducing dimensionality. Subsequently, a DPM is trained on this compressed latent space instead of the high-dimensional pixel space, enhancing efficiency and allowing rapid generation from latent space back to detailed images. This method not only makes high-resolution image generation computationally feasible on limited setups but also speeds up the entire process, maintaining the quality and adaptability of the original DPM approach.
|
 Stable Diffusion Overview
Stable Diffusion Overview
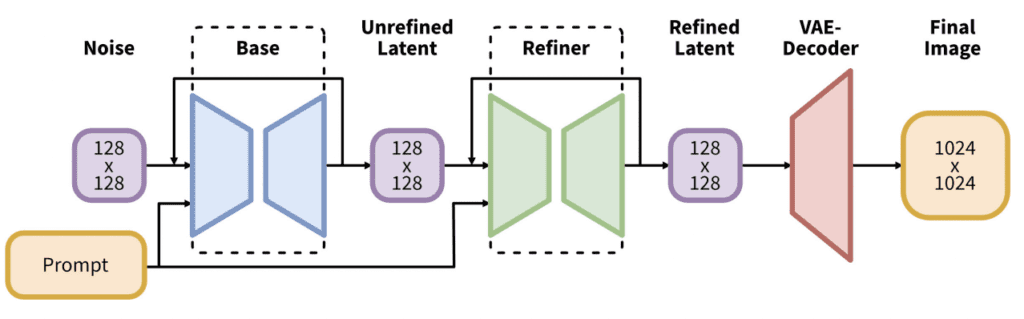
Stable Diffusion, introduced in 2022, marks a significant advancement in generative AI, enabling the creation of photorealistic images and animations from textual and visual prompts using diffusion processes and latent space rather than pixel space. This approach dramatically reduces the computational load, allowing efficient operation on standard desktop GPUs. It features a variational autoencoder (VAE) that compresses images without losing detail and quality, supported by expansive datasets from LAION. Stable Diffusion incorporates forward and reverse diffusion processes and a noise predictor, all facilitated by text conditioning. These components not only allow for detailed image generation but also extend to animating these images into GIFs, meeting the demands of personalized text-to-GIF synthesis with temporal cohesion and visual richness.
|
 Make A Video Overview
Make A Video Overview
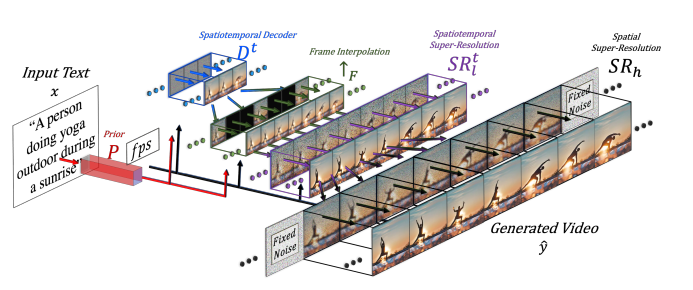
Make-a-Video leverages the advancements in T2I generation for the creation of T2V content, using the appearance and language descriptors of the world from image-text pairs, while discerning motion from unlabelled video data. This method gives 3 major benefits: expediting T2V model training without necessitating the development of visual and multimodal foundations anew, eliminating the dependency on paired text-video datasets, and ensuring the generated videos reflect the extensive diversity encountered in modern image synthesis. Its architecture extends T2I models with spatial-temporal components, decomposing and approximating temporal U-Net and attention tensors across space and time, enabling it to produce videos of high resolution and frame rate. Make-A-Video's proficiency in adhering to textual prompts and delivering high-quality videos has established new benchmarks in the T2V domain.
|
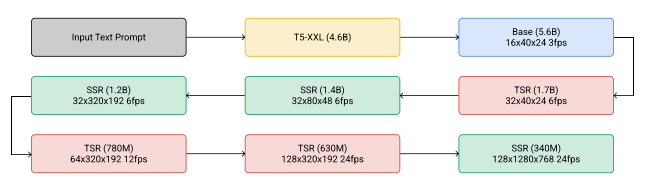 Image Video Overview
Image Video Overview
Imagen Video introduces a text-conditional video generation system that leverages a cascade of video diffusion models to produce high-definition videos from textual prompts. This system employs a foundational video generation model alongside a series of spatial and temporal video super-resolution models that interleave to enhance video quality. The architecture incorporates fully-convolutional temporal and spatial super-resolution models at varying resolutions, utilizing v-parameterization for diffusion processes, thereby scaling the model effectively for high-definition outputs. By adapting techniques from diffusion-based image generation and employing progressive distillation with classifier-free guidance, Imagen Video achieves not high fidelity and rapid sampling rates while also providing a high degree of controllability and depth of world knowledge. This allows for the creation of stylistically diverse videos and text animations that demonstrate a sophisticated understanding of 3D objects.
|